什么是分散加载?
简单来说就是让编译器告诉MCU内核哪里存的是代码、哪里存的是数据,去哪个特定的地址找到下一步需要运行的函数的东东,就是告诉编译器把每一个编译好的函数、数据放到具体的哪一个物理地址的东东。当然你可以对链接器的工作漠不关心,但经常你的工程比较复杂时,你就需要指导你下属的具体工作了。
分散加载能做什么?
还记得我们之前的文章中讲过的,一般来说在Keil MDK工程中的默认程序各个部分的摆放如下图所示(示例,其他Cortex-M系列MCU的程序摆放与之类似):
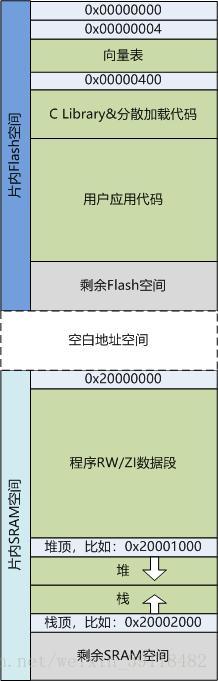
大家有没有想过为什么是这样的摆放?或者说是谁决定了程序是这样的摆放?或者我们能否定义自己的摆放?
举几个常用的必须通过修改分散加载脚本的常见用法,如下:
1.Bootloader & 程序升级
Bootloader的原理就简单来说在MCU的Flash里面同时摆放2个不同工程的程序,一个Bootloader程序和一个用户程序,那么这就需要调整分散加载文件,以达成在一个Flash里面同时摆放两个不同程序的目的。

程序升级的原理类似,需要特别说明的一点是,现在IOT大行其道的背景下,程序的远程无线升级就是一个刚需,但是这里存在一个问题,就是IOT的无线技术往往功耗低(换句话说就是速度慢),升级所有代码对电池的开销是很大的,而往往程序升级都是为了增加一个小功能或修复一个小BUG,不需要全部升级而是只升级一点点。当然要实现这个功能同样需要分散加载的配合,把可能会后续升级的部分函数或数据事先分配好空间,留好空间上的余量,这些都需要分散加载来完成。
2.加速程序运行速度(如:对速度有较高要求的算法等)
比如项目上有一段代码,你需要CPU以尽可能快的速度跑这个代码,通常是时间紧要的算法等,当然你除了优化C代码以尽可能提高其执行效率外,还有一种方式可以将程序运行速度提升20~50%,这就是把代码加载到RAM里面去运行。
根据具体执行内容的差异,由于绝大多数Cortex-M系列的MCU里面没有分支预测单元所以理论上跳转语句越多,执行效率提升越明显。
其原理是,MCU内部集成的Flash受限于其工艺(必须兼容MCU内核工艺)以及一些其他原因,导致读取速度较慢。
顺序执行还好,现在的Cortex-M系列MCU一般都集成Flash加速单元,说白了,就是一个FIFO,一次从Flash里面顺序的读出150条左右的指令。CPU的i-code总线直接访问FIFO读取指令,FIFO速度极快,与MCU内核可以运行于同一主频下,这样可以避免访问Flash造成的时钟等待,但是如果有if-else/switch-case等分支语句就麻烦了,因为程序执行到分支语句时极有可能不是顺序执行,这样就造成了FIFO里面取出来的指令无效,需要重新读取Flash中的指令,这就慢了。
一般来说MCU片内集成的Flash等效读取速度在24-72MHz之间,72MHz算很快的,也就是说如果你的MCU主频跑到120MHz,但你的Flash读取等效速度只有32MHz,那你想一下你的程序运行速度会怎样?因为有Flash加速器的原因你的MCU运行速度会快于32MHz,但又因为有分支,所以你的真实执行速度会介于32MHz~120MHz之间,之前我还专门测过,我之前的一个工程代码测试的结果120MHz主频的MCU真实运行速度是接近85MHz,你的MCU性能缩水了……。
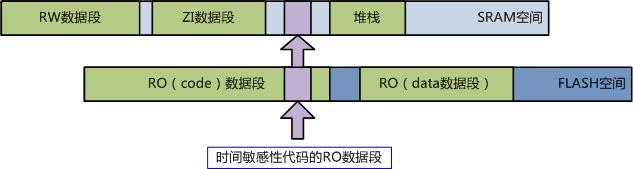
那怎么样提升呢?减少分支是一方面,但还有一个更好的方式,就是把代码的RO(code)段加载到片内SRAM里面运行!因为片内SRAM的速度是极快的,完全跟得上MCU内核的速度,也就是说120MHz的MCU内核其片内SRAM的等效运行速度也是120MHz。
但这里也有一个问题,你也发现了,就是几乎所有的MCU都是Flash容量>SRAM容量。这是因为在MCU片内做SRAM的成本很高,很占晶元面积(晶元面积就是芯片成本的重要来源)。不是片内SRAM做不大,而是做大了就买不起了!这也就是电脑的Intel CPU缓存大小直接影响成本的原因,电脑的i5、i7处理器里面的缓存就是SRAM,所以你发现缓存越大的CPU价格越高就是这个道理。
扯远了,我们再扯回来……,把代码加载到SRAM里面运行最大的问题就是SRAM空间往往太宝贵了,以至于我们几乎不可能把所有代码加载到SRAM中去运行,所以我们只能把最需要快速运行的代码加载到SRAM中去,这当然需要分散加载的配合。如下图:
3.访问扩展存储&对存储区的划分
如果你只用于数据扩展,那可以不必动用分散加载,但是如果你要把外扩的存储用于运行代码/扩展RW数据段等用途,简单来说就是把片内地址映射到片外,需要按照寻址空间的方式来访问扩展存储的话,比如扩展Nor-Flash、扩展SDRAM、扩展SRAM等,那就需要分散加载配合。
存储区里面每个区域存储什么样的内容也可以由分散加载指定,这个我们会在下一篇文章里面探讨具体实现的方法以及分散加载脚本的语法等内容。
其实分散加载的应用有还有很多,以后我们会慢慢提及。
分散加载的脚本
要使用分散加载脚本可以在以下地方设置:
勾掉“Use Memory Layout from Target Dialog”复选框里面的对号,就可以使用自己定义的分散加载文件。
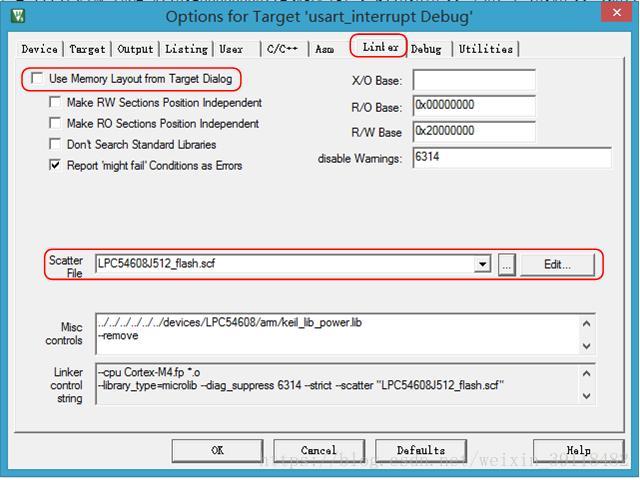
如果勾选了这个对号,那么就将使用系统默认的分散加载文件,那个货很狗屎,最多就是仅能保证能用。
分散加载的基本结构定义以及分散加载的目的
- Code段:表示程序代码部分,就是你编写的各种if-else/switch-case/for/函数……等代码
- RO-data段:程序定义的所有常量以及const类型数据
- RW-data段:已经初始化的所有静态变量
- ZI-data段:未初始化的静态变量
- RO段:指Code以及RO-data的统称
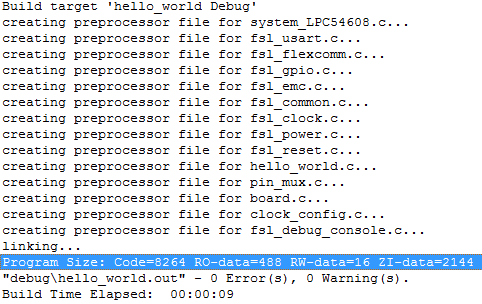
我们可以在编译链接完层的代码后,链接器的输出打印上看到这部分信息,如下图,就是一个Hello World工程的输出打印,其中链接器打印出了这几个段的大小(蓝色底纹部分):
如果大家想看更详细编译结果,可以双击工程名查看.map文件,之前文章介绍过的:
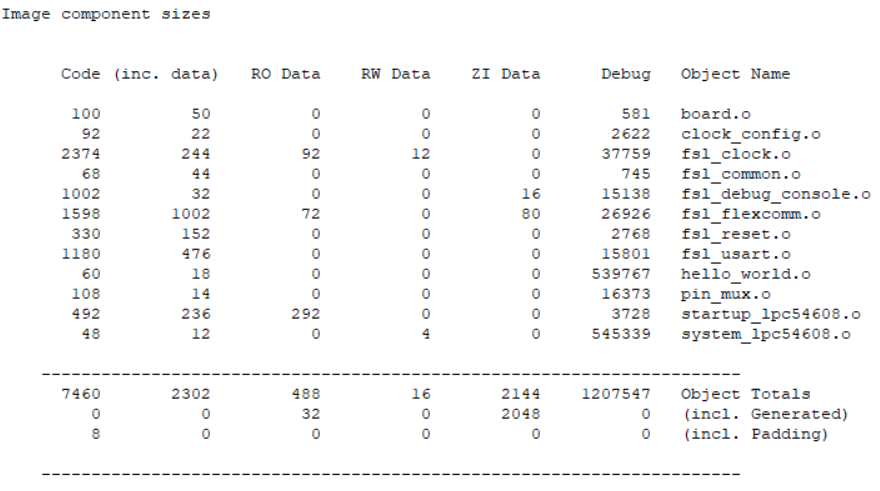
.map文件最后有关于编译结果的详细介绍,我是用的这个hello world工程中的所有被编译&链接的文件都会在.map(链接器的工作报表)文件里面详细记述,每一个文件编译后产生的Code、RO-Data、RW、ZI的大小,以及加在一起的总大小,如下图:
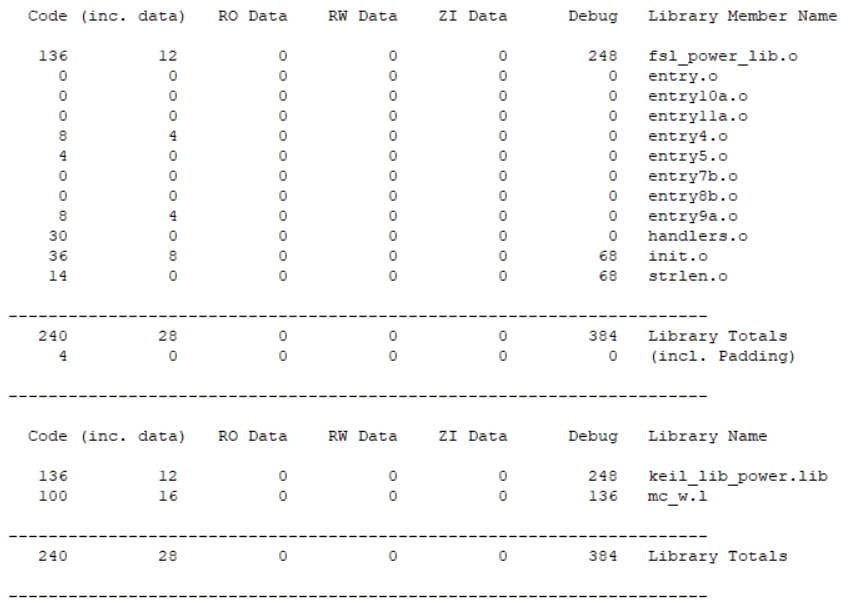
上图部分是用户代码编译形成各个部分的Code、RO-Data、RW、ZI数据段情况,我们之前说过你的工程中除了你的用用户工程代码意外还有C Library、分散加载以及一些ARM的底层代码在,那么部分编译产生的Code、RO-Data、RW、ZI数据段情况如下图所示(也是在.map文件中):
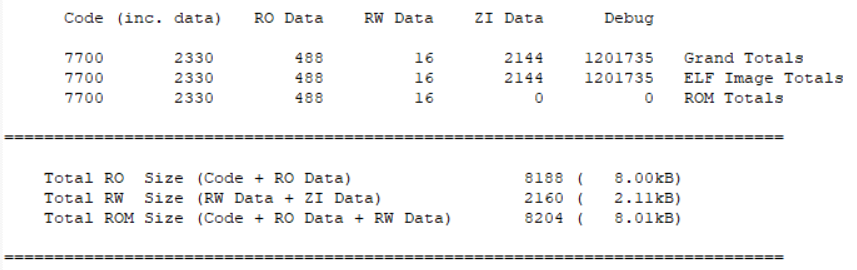
用户代码以及C Library、分散加载以及一些ARM的底层代码编译产生的最终总结果如下图所示:
RW+ZI数据段最终运行时会占用片内SRAM或外扩的RAM存储器,而Code+RO-data+RW-data数据最终会产生对片内Flash的占用或外扩程序存储区的占用。
这里要说明的一点是RW以及ZI数据段的初始化是在分散加载过程中完成的,也就是在__main中完成的,比如你定义一个全局变量,并给它赋值,只有在__main结束后你才能看到这个全局变量被赋值成功的,也就是说在__main之前,使用全局变量是行不通的。
所以分散加载的根本目的就是:
把RO-data数据段、RW数据段、从片内程序存储区里面(一般是片内Flash),搬到片内程序运行区(一般是片内SRAM);
在片内程序运行区(一般是片内SRAM)内分配ZI数据段运行需要的空间并把这段数据初始化为0;
初始化堆栈;
对于有些指定加载到程序运行区(一般是片内SRAM)的RO数据段,把他们加载到程序运行区(一般是片内SRAM)里面。
这个跟我们使用的电脑运行操作系统或者软件原理类似,电脑就是把硬盘里面的操作系统加载到内存里面,然后CPU从内存里面取数据以及程序指令来运行的。
下面几篇文章我们将深入探讨分散加载的使用。
转自:https://blog.csdn.net/weixin_39118482/article/details/79849133
